
Name: avs-device-sdk
Owner: Alexa
Description: An SDK for commercial device makers to integrate Alexa directly into connected products.
Created: 2017-02-09 18:57:26.0
Updated: 2018-05-24 07:55:26.0
Pushed: 2018-05-23 07:41:19.0
Homepage: https://developer.amazon.com/avs/sdk
Size: 1298833
Language: C++
GitHub Committers
| User | Most Recent Commit | # Commits |
|---|
Other Committers
| User | Most Recent Commit | # Commits |
|---|
Significant changes have been made to the authorization process and the AlexaClientSDKConfig.json configuration file in v1.7 of the AVS Device SDK. Click here for update instructions.
See release notes for a complete list of updates, enhancements, bug fixes, and known issues for this release.
The Alexa Voice Service (AVS) enables developers to integrate Alexa directly into their products, bringing the convenience of voice control to any connected device. AVS provides developers with access to a suite of resources to quickly and easily build Alexa-enabled products, including APIs, hardware development kits, software development kits, and documentation.
The AVS Device SDK provides C++-based (11 or later) libraries that leverage the AVS API to create device software for Alexa-enabled products. It is modular and abstracted, providing components for handling discrete functions such as speech capture, audio processing, and communications, with each component exposing the APIs that you can use and customize for your integration. It also includes a sample app, which demonstrates the interactions with AVS.
You can set up the SDK on the following platforms:
You can also prototype with a third party development kit:
Or if you prefer, you can start with our SDK API Documentation.
Watch this tutorial to learn about the how this SDK works and the set up process.

This diagram illustrates the data flows between components that comprise the AVS Device SDK for C++.
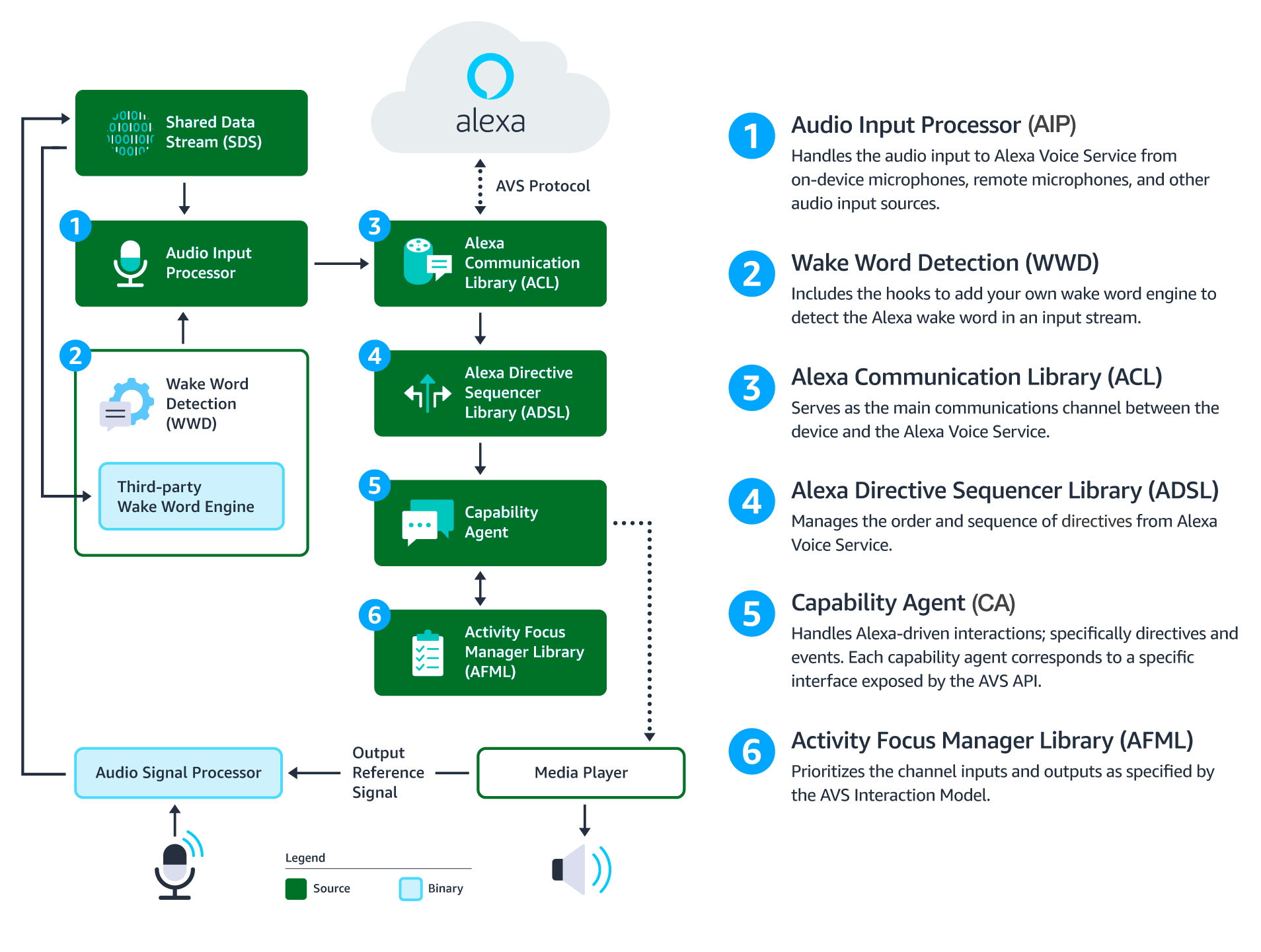
Audio Signal Processor (ASP) - Third-party software that applies signal processing algorithms to both input and output audio channels. The applied algorithms are designed to produce clean audio data and include, but are not limited to acoustic echo cancellation (AEC), beam forming (fixed or adaptive), voice activity detection (VAD), and dynamic range compression (DRC). If a multi-microphone array is present, the ASP constructs and outputs a single audio stream for the array.
Shared Data Stream (SDS) - A single producer, multi-consumer buffer that allows for the transport of any type of data between a single writer and one or more readers. SDS performs two key tasks:
SDS is implemented atop a ring buffer on a product-specific memory segment (or user-specified), which allows it to be used for in-process or interprocess communication. Keep in mind, the writer and reader(s) may be in different threads or processes.
Wake Word Engine (WWE) - Software that spots wake words in an input stream. It is comprised of two binary interfaces. The first handles wake word spotting (or detection), and the second handles specific wake word models (in this case “Alexa”). Depending on your implementation, the WWE may run on the system on a chip (SOC) or dedicated chip, like a digital signal processor (DSP).
Audio Input Processor (AIP) - Handles audio input that is sent to AVS via the ACL. These include on-device microphones, remote microphones, an other audio input sources.
The AIP also includes the logic to switch between different audio input sources. Only one audio input source can be sent to AVS at a given time.
Alexa Communications Library (ACL) - Serves as the main communications channel between a client and AVS. The ACL performs two key functions:
Alexa Directive Sequencer Library (ADSL): Manages the order and sequence of directives from AVS, as detailed in the AVS Interaction Model. This component manages the lifecycle of each directive, and informs the Directive Handler (which may or may not be a Capability Agent) to handle the message.
Activity Focus Manager Library (AFML): Provides centralized management of audiovisual focus for the device. Focus is based on channels, as detailed in the AVS Interaction Model, which are used to govern the prioritization of audiovisual inputs and outputs.
Channels can either be in the foreground or background. At any given time, only one channel can be in the foreground and have focus. If multiple channels are active, you need to respect the following priority order: Dialog > Alerts > Content. When a channel that is in the foreground becomes inactive, the next active channel in the priority order moves into the foreground.
Focus management is not specific to Capability Agents or Directive Handlers, and can be used by non-Alexa related agents as well. This allows all agents using the AFML to have a consistent focus across a device.
Capability Agents: Handle Alexa-driven interactions; specifically directives and events. Each capability agent corresponds to a specific interface exposed by the AVS API. These interfaces include:
In addition to adopting the Security Best Practices for Alexa, when building the SDK:
Note: Feature enhancements, updates, and resolved issues from previous releases are available to view in CHANGELOG.md.
v1.7.1 released 05/04/2018:
Enhancements
A2DP-SINK and AVRCP profiles. Note: Bluetooth is optional and is currently limited to Raspberry Pi and Linux platforms.DCF) renamed to Capabilities.Bug Fixes
MediaPlayerTest failed on Windows.Known Issues
ACL may encounter issues if audio attachments are received but not consumed.SpeechSynthesizerState currently uses GAINING_FOCUS and LOSING_FOCUS as a workaround for handling intermediate state. These states may be removed in a future release.GStreamer pipeline and the Bluetooth agent.BlueALSA must be terminated each time the device boots. See Raspberry Pi Quick Start Guide for more information.